How Snowplow Analytics Works
To track a website, application or IoT hardware, Snowplow Analytics uses trackers, small pieces of code that execute on given conditions, which generate event-level data that is then processed and analyzed in your infrastructure (Amazon Web Services, and soon on Google Cloud and Microsoft Azure).
See the video below explaining what Snowplow is and how it works.
Snowplow Analytics has two possible ways of processing data: real-time or batched.
Batched Pipeline
In a batched pipeline configuration, the data is processed at regular time intervals, given by your business requirements and stored in a database for analysis.
Real-time Pipeline
In a real-time pipeline configuration, the data is processed and made available for analysis in real-time.
Analysts create models of the data to answer business questions and use a data visualization layer to communicate and automate reports.
Essential Reads: Snowplow Analytics
Professional Services Solutions Learn More About SnowplowSnowplow Analytics Architecture
The map below explains the Snowplow Analytics architecture for the two pipelines, real-time and batched.
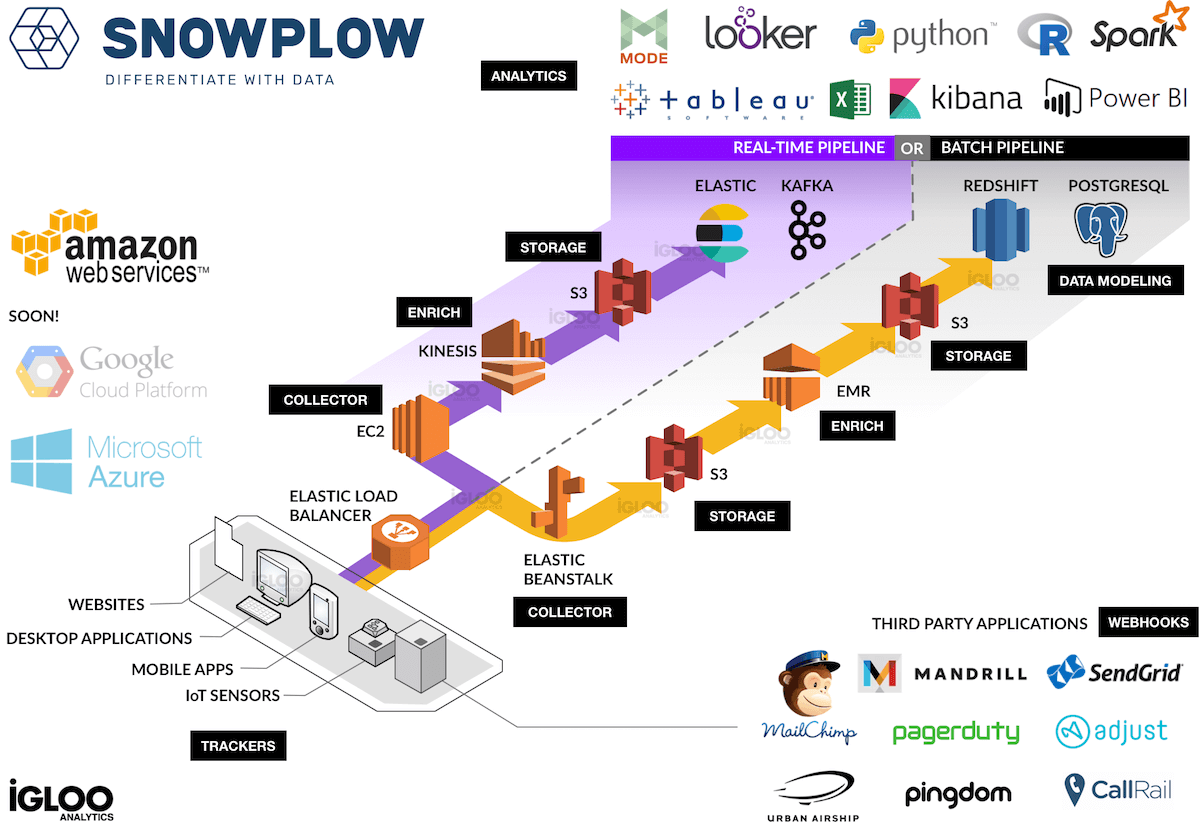
- Trackers fire Snowplow events. Currently, there are 16 trackers available which can track anything from a website to IoT sensors.
- Collectors receive events from trackers. There are three event collectors: Amazon Elastic Beanstalk, Apache Kafka or Amazon Kinesis.
- Enrich cleans up and enriches raw events and sends them to storage. Currently, there is a Hadoop-based enrichment process (EMR), and a Kinesis, or Kafka-based process.
- Storage is where the enriched Snowplow events live. Currently, Snowplow support Amazon S3, Amazon Redshift or Postgres databases.
- Data Modeling is where event-level data is joined with other datasets and aggregated according to business requirements.
- Analytics is where you productize analysis and create reports from Snowplow events.